Some time ago, my organization had the need to have a new company established in AX. The direction given to us was that this company was to have their own sets of books for tax and reporting purposes, but manufacturing would continue to be done within our primary company, which was facilitated by the AX Intercompany functionality.
More recently, the directive came that this other company should no longer exist - there actually isn’t any need to have the financials separated from the primary organization, and the intercompany transactions are adding too significant an overhead to our processes to justify its continuation.
This put us in an interesting position: we now need to merge the data from one company into another company so users will only need to operate in one.
We explored several options to move data from one side to another. The biggest benefit was that, because both companies are in AX 2009, we have the same database backend, and a majority of the settings are identical. During this exploration, we looked at several possible solutions: using the AX Data Import/Export tool, using Atlas, duplicating the records in SQL directly and updating the DataAreaId, and others. No solution seemed to have an ideal migration path: while some settings like parameters were the same between the companies, others like item groups and financial dimensions had diverged and did not have matching codes on both sides.
This was most detrimental to the most promising solution, Atlas. Not only would we have to create an upload template or series of templates that holds the base data like sales orders and items, we would also have to have supplementary templates to handle dependent information and explicitly add all the missing information prior to the main import. This ends up being a very tedious process, where even one missing entry at any point could cause the entire process to fail. Additionally, because we were going to have a hard cutoff of when the other company would stop being used, we would have to monitor those dependencies until just prior to the import to make sure no new information was added.
During all this, we also found a fatal fault in both the Atlas plan and the Data Import/Export tool: In a few cases, the amount of information we need to import is massive. Since both the import/export tool and Atlas are dependent on Excel to operate, we were running into stability and performance issues using them. Items (the InventTable) in particular caused Excel to outright freeze or even crash, rendering both solutions effectively useless.
Being a developer, I began approaching it from a data-driven context. I had some requirements in mind when approaching it:
- The tool had to be simple to use. Since I would not have access to use it in the production environment, I could not rely on a ‘developer interface’. This would have to include a progress indicator as well.
- The tool should be able to identify missing information and be able to adapt either by translating or creating the information, depending on requirements.
- The tool should allow users to specify what is imported. This can be accomplished either by providing an explicit ‘include’ list or exclude filter.
- If some data is explicitly or implicitly to be added but it already exists (according to a table’s primary key), it should be assumed that the information that is already there is the correct version, and it should be skipped.
- A log of some sort should be generated which shows what information was added (for review purposes post-import).
During the process, we were also able to identify the information we wanted to import:
- Customers
- Vendors
- Items
- Open Sales Orders
- Open Purchase Orders
- Open Quotes
- Open Customer Balances
- Open Vendor Balances
- General Ledger Balances
Because we already had Atlas templates to handle open customer and vendor balances, we opted to use those for balances. Everything else would be done using this new tool.
In the end, this is what we ended up with:
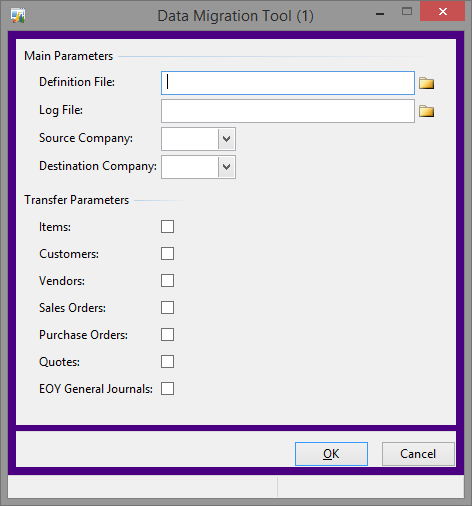
The definition file requested is an Excel file. The file has one tab for each of the items under ‘Transfer Parameters’ (except EOY General Journals). For each tab, there is simply a list of those objects – the Items tab has a list of items, the Sales Orders tab has a list of sales orders, etc. The user only need to check what information should be copied, not necessarily what was available in the data file. This allows us to run the tool multiple times, if necessary.
The log file that is generated is a CSV file. If there is no file specified, it instead writes everything to the infolog.
Prior to starting, the tool opens the definition file and counts how many of each object are in the list, giving us the basis of a progress dialog, and begins the transfer of each selected module one at a time. Each module is wrapped in a transaction to prevent any partial information from being added if there is an error. However, each module is handled independently so if one fails it simply proceeds to the next.
To accomplish the data transfer, I created a supporting data copy class. Each method of the class is named after a table, and takes a record of that table as a parameter. The methods are responsible for copying the record passed in (which should be from the Source Company) and inserting it into the Destination Company. It’s also responsible for ensuring that any dependencies necessary to copy that record are defined, and any sub-records related to the record are also defined. For example, CustTable ensures things like the Customer Group exist, copies the customer record, and also triggers the creation of the necessary entries in the Global Address Book. This creates an interesting web of dependencies which mimic the requirements by AX. This means you can effectively say “All I know is I have this sales order. Copy it over.” The web of requirements will cause the tool to verify the customer, financial dimensions and other properties exist (creating them if necessary), create the order header, and then add each of the lines (including the items if necessary, which can in turn require a BOM and further items and/or vendors) to the order.
Here is an example of one of the methods:
1 | void inventDim(InventDim srcRecord) |
The method checks to make sure the record doesn’t already exist, checks the Site, Warehouse and Location to verify they exist (or create them if they don’t), adds the record, and then adds any document handling attachments associated with the record. We don’t use Batch, Pallet, Serial, Configuration, Size or Color, so we don’t bother to check those (if you do, you will need to follow the pattern to check those).
The biggest benefit to having a web like this is we don’t need to define all the dependencies across modules. For example, if we missed a customer in the customer list, and that customer was used on a sales order that is on the sales order list, the customer will still be added. To this end, we can focus on making each list stating what must be copied, even if it is not used anywhere else. If we have a list of items we must have no matter what, we put those on the list. But if we have other items we only want to bring over if they are used, we can leave them off and trust that sales orders, purchase orders or quotes will create them if needed. This significantly reduces overhead during the transfer - in our case, we were able to keep a considerable number of items from being added to the destination company, which helps reduce confusion to users of both companies.
After each record that is inserted, an entry is logged (either to the CSV file, or to the infolog) which specifies exactly what was added. If any warnings or errors are generated, they are also logged.
Needless to say, there is still a fair amount of overhead the way the data is copied: since AX is handling both the retrieving and inserting of the data, there are many calls to the changecompany function. However, in development testing we are still seeing transfer rates of about 20-30 records per second. Our testing data file contained just under 1000 objects to transfer, expanded to about 4700 records after applying the dependency web, and takes about 5 minutes to complete.
The only downside to the tool is portability. We cannot do something like this:
1 | static void job1(Args _args) |
While this would be nice to have, and seems like it should work to copy all the fields from the source record to an empty buffer. However, this also copies fields like the RecId and DataAreaId; when you go to insert the record, a runtime error is thrown that the record already exists (which, based on those two fields, is does). Instead, the pattern needs to be:
1 | static void job1(Args _args) |
Each field needs to be called explicitly. This tends to be verbose, and any custom fields will also need to be added to the list. It could be possible to make this generic by using DictField and related classes, but doing that prohibits you from easily applying field translations (which we are doing for inventory locations and a few other places). Having to explicitly list all the fields means that if we add fields to any of the tables in the tool and want to use this tool again, it will need to be updated to include the new fields. This also means we can’t easily share this with another organization; it would require some amount of effort to make sure the field lists are correct. However, getting the list of fields is easy within the AOT: if you select all the fields on a table and right-click, navigate to “Add-Ins”, “Copy”, and “Name” you will have every field copied to your clipboard. Combine this with an Excel spreadsheet and you can have it format the list (each line being “destinRecord.” + fieldname + “= sourceRecord.” + fieldName; you can even write in something that moves each “=” to the nearest AX tab stop), which can be copied directly in with minimal effort.
After it was all said and done, the tool made it incredibly easy to copy the data from one company to another - all you need is the list of objects from your users.
I have also attached the XPO for the core class (not the data copy class) for reference, so you can get an idea as to how the process is organized.