Read the other posts in this series:
Why Create an AX Build Server/Process?
Part 1 - Intro
Part 2 - Build
Part 3 - Flowback
Part 4 - Promotion
Part 5 - Putting it all together
Part 6 - Optimizations
Part 7 - Upgrades
In this part of my Automated Build and Code Deployment series, I’ll be going over one of the more critical aspects: the build itself. I’ll outline exactly what happens during the build process, including code examples where necessary. The automation does require some changes to AX to help it run more efficiently.
To help orchestrate every step of the build process, we are using TeamCity, an easy to use continuous integration tool (http://www.jetbrains.com/teamcity/), and a series of short and simple powershell scripts. To help with the process, we keep all the scripts under VCS which is then linked to TeamCity. If any changes occur to the scripts, the changes are applied prior to running any tasks.
The TeamCity Agent responsible for running the tasks is installed on the build server, running under a dedicated user that has administrative rights. The user is also granted administrative rights in AX (Build only) so it can run the Sync and Compile commands.
To help, here’s an overview on how TeamCity can help to accomplish the goals as ideals I set in my previous post:
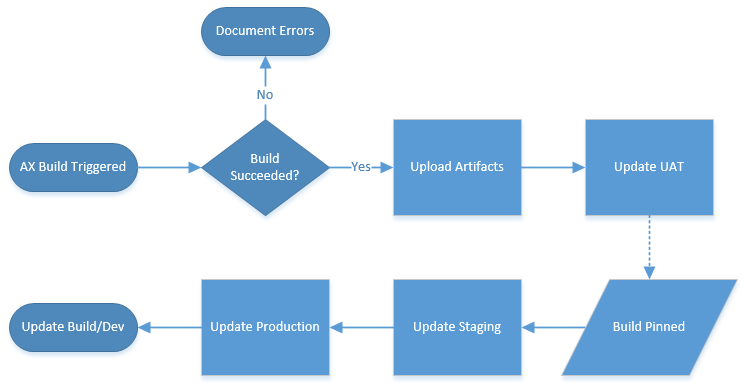
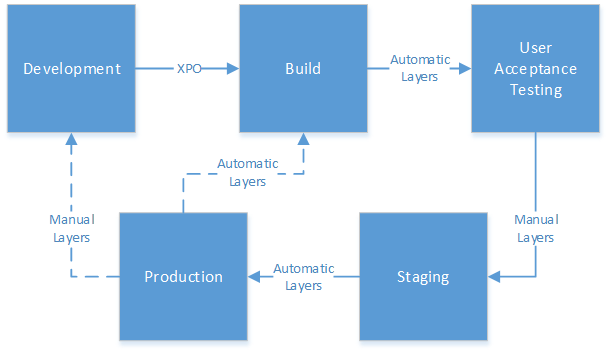
All the processes except for one are automated. In this case, the Build Trigger is a scheduled item, as is the update from Staging to Production and UAT to Staging. However, the artifacts used on UAT and Staging are different depending on the conditions of the build. UAT will use the artifacts from the last successful build (and will process as soon as the Build is completed), while staging will use the artifacts from the most recent pinned build. Because pinning a build is a manual process, and the ability can be restricted to certain users, it makes the ideal condition to determine the code that gets pushed to Staging. However, in TeamCity artifacts from pinned builds are kept indefinitely regardless of the cleanup plan you specify. We are planning on only keeping 3-4 builds pinned at any given time, so we can manage the space artifacts take up and still have enough history to rollback if necessary.
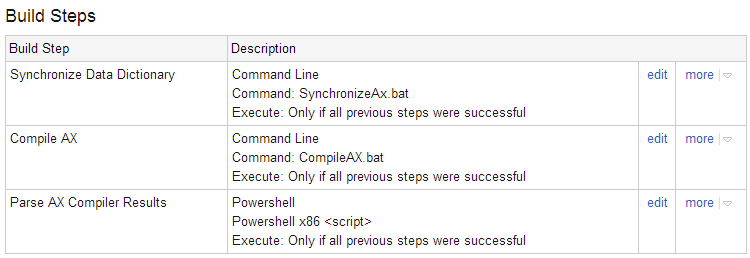
The actual AX build consists of 3 steps: Synchronize the Data Dictionary, compile the code, and figure out what happened. Our build process will address all three of these steps. If any additional requirements come up, TeamCity makes it easy to add new steps so we can make sure those happen as well. Because the scripts are wrapped in a VCS, it’s easy to make script modifications and to track when a change happened.
AX already has built-in command line commands to help handle the Data Dictionary synchronization and the system compile. Both commands will automatically close AX when the process is complete. In addition, the system compile command automatically takes the compiler output and saves it to a file, for later analysis. However, the normal output file is an HTML file with embedded XML output from the tmpCompilerOutput table, which holds all the information you normally see on the compiler. Because the HTML file does not render properly on modern browsers (it only works on Internet Explorer 9 and earlier, and even then does not do all it should if you examine the source), I have opted to change the SysCompilerOutput class so it outputs directly to a .xml file with only the pure XML. This also makes it easier to parse the results. If you want to do the same, here’s how:
1 | //Change |
1 | //Comment out or remove the following lines: |
If you would rather keep the HTML file and use it instead, you will need to make some changes to the script to account for the extra XML nodes. In addition, you will likely need to account for the XML header information (<?xml version="1.0" encoding="UTF-8"?>), as it may lead to parsing errors.
The actual build configuration in TeamCity is rather simple, only 3 steps:
SynchronizeAx.bat:1
ax32.exe -startupcmd=synchronize
CompileAx.bat:1
ax32.exe -startupcmd=compileall_+
The Parse AX Compiler Results task is little stranger, but only because TeamCity currently has a bug that causes it not to use the correct return value from PowerShell scripts.
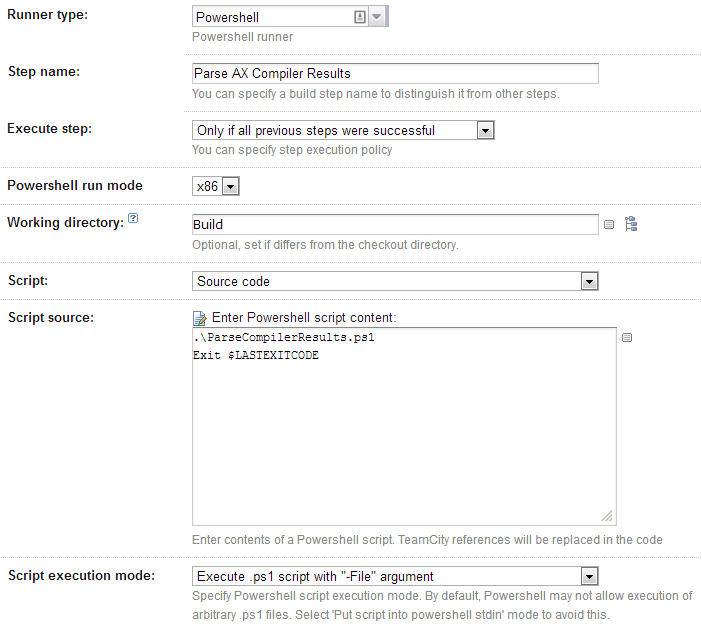
The script source allows the script to run, and returns the error code from that script if there is any.
ParseCompilerResults.ps1 looks like this:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54trap
{
# On any thrown error, return with a non-zero exit code
exit 1
}
if ($env:TEAMCITY_VERSION) {
# When PowerShell is started through TeamCity's Command Runner, the standard
# output will be wrapped at column 80 (a default). This has a negative impact
# on service messages, as TeamCity quite naturally fails parsing a wrapped
# message. The solution is to set a new, much wider output width. It will
# only be set if TEAMCITY_VERSION exists, i.e., if started by TeamCity.
$host.UI.RawUI.BufferSize = New-Object System.Management.Automation.Host.Size(8192,50)
}
[xml]$xml = (Get-Content "C:\Users\Public\Microsoft\Dynamics Ax\Log\AxCompileAll.xml")
$ns = @{ Table = "urn:www.microsoft.com/Formats/Table" }
$errorNodes = Select-Xml -XPath "/AxaptaCompilerOutput/Table:Record[Table:Field[@name='SysCompilerSeverity'] = 0]" -Xml $xml -Namespace $ns
$warningNodes = Select-Xml -XPath "/AxaptaCompilerOutput/Table:Record[Table:Field[@name='SysCompilerSeverity'] > 0 and Table:Field[@name='SysCompilerSeverity'] < 255]" -Xml $xml -Namespace $ns
$todoNodes = Select-Xml -XPath "/AxaptaCompilerOutput/Table:Record[Table:Field[@name='SysCompilerSeverity'] = 255]" -Xml $xml -Namespace $ns
$success = $true
foreach ($node in $errorNodes)
{
$success = $false
$nodePath = ($node.Node.Field | ? { $_.name -eq "TreeNodePath" }).'#text'
$message = ($node.Node.Field | ? { $_.name -eq "SysCompileErrorMessage" }).'#text'
write-host "##teamcity[message text='${nodePath}: $message' status='ERROR']"
}
foreach ($node in $warningNodes)
{
$nodePath = ($node.Node.Field | ? { $_.name -eq "TreeNodePath" }).'#text'
$message = ($node.Node.Field | ? { $_.name -eq "SysCompileErrorMessage" }).'#text'
write-host "##teamcity[message text='${nodePath}: $message' status='WARNING']"
}
foreach ($node in $todoNodes)
{
$nodePath = ($node.Node.Field | ? { $_.name -eq "TreeNodePath" }).'#text'
$message = ($node.Node.Field | ? { $_.name -eq "SysCompileErrorMessage" }).'#text'
write-host "${nodePath}: $message"
}
if ($success -eq $false)
{
throw $_
}
The top of the script (before [xml]$xml = Get-Content…) sets a generic error handler to return a non-zero error-code when it fails, and sets the TeamCity Runner to a wider screen size. The screen size is necessary because otherwise there is a good change the ###teamcity messages will not be parsed correctly because they are too long. You can tweak the script as necessary (by adding $success = $false to any of the other foreach blocks) to raise your quality bar as you see fit.
It would also be wise to adjust the Build Failure conditions to include “an error message is logged by a build runner” and “build process exit code is not zero”. You can define additional failure conditions as desired.
Finally, we have artifact paths set as follows:1
2
3
4
5C:\Program Files\Microsoft Dynamics AX\50\Application\Appl\DynamicsAx1\*.ald => BuildFiles.zip
C:\Program Files\Microsoft Dynamics AX\50\Application\Appl\DynamicsAx1\*.add => BuildFiles.zip
C:\Program Files\Microsoft Dynamics AX\50\Application\Appl\DynamicsAx1\*.ahd => BuildFiles.zip
C:\Program Files\Microsoft Dynamics AX\50\Application\Appl\DynamicsAx1\*.aod => BuildFiles.zip
C:\Program Files\Microsoft Dynamics AX\50\Application\Appl\DynamicsAx1\*.khd => BuildFiles.zip
This allows all the data files to packed up into a single zip file, which is then uploaded to TeamCity for later use. Interestingly enough, even though these are binary files (except the label files, which are plaintext) we are still getting a 10% compression ratio, meaning our 3.5GB of files are compressed to 350MB.
That’s all there is to it! Once it’s set up, build will happen automatically. Combined with some tools that hook into TeamCity, like VisuWall, you can easily identify where any issues may be:
As you can see, the AX Build process is failing. The build log for the build contains the details of what failed. In our case, some classes contain a syntax error that need to be fixed. In our process, this would not trigger an update of UAT until it was fixed.
This screen is on display for everyone to see in our IT area, and updates in realtime. When we fix those classes, the block will turn green like the rest of the board. Plus, the AX process displays the same way the rest of our projects do, making it an easy way to know what’s happening in development.